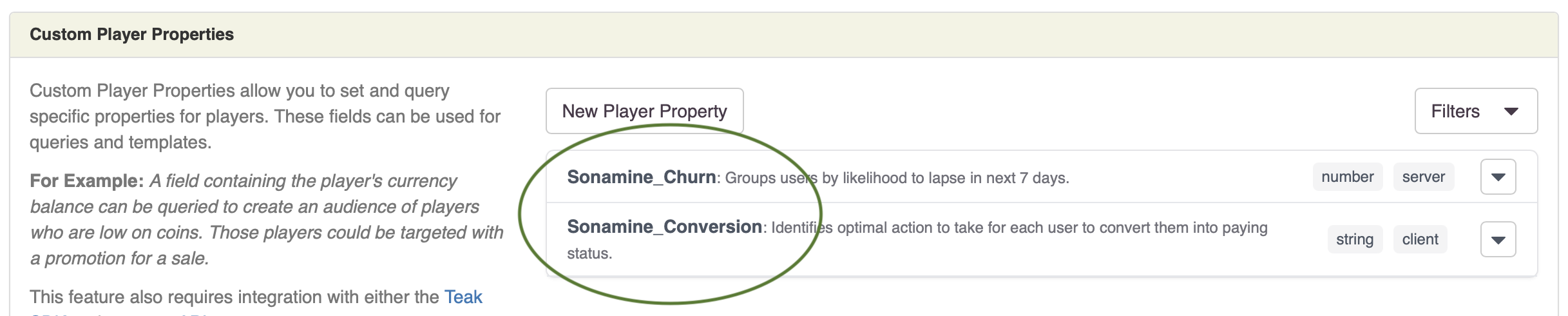
Free Player Retention Guide Get Now
We will start the new year with a series of articles about productionized machine learning. We will introduce a broad conceptual challenge and illustrate our solution. First up is model drift and retraining.
Model drift is the idea that a predictive model degrades over time. The usual culprit is that the real life environment is diverging from the modeling dataset. So the modeling dataset no longer matches the current environment. How quickly this happens really depends on the domain and the type of model. Sonamine focuses on consumer facing entertainment apps, and conditions there change rapidly.
Let's review a real life example, taken from a Sonamine customer for whom we are trying to predict a specific user behavior. It's a binary classification model with hundreds of thousands to millions of users. The data distribution is not heavily skewed with hundreds of input features. In short, it is a pretty generic classifier.
While there are many different model performance measures such as accuracy and precision, in real life, these performance measures are too broad based and usually do not correspond to the particular use case of the model. This particular model was being used to alter the end user experiences based on the predicted probabilities of class membership. So the more relevant model performance here is whether the predicted probabilities match up to the actual outcome probabilities.
By plotting the predicted probability against the actual outcomes, we can visualize this aspect of model performance. A perfect model will have a straight line with formula y=x. If we generate the same scatterplot based on the use of different models built at previous times, we can compare how these different models perform.
The blue line in Figure 1 below shows a model built right before the scoring dataset was generated. The green line shows a model built one day earlier. Couple of quick points jump out (1) the predicted probabilities match up very nicely with actual outcomes. (2) The difference between models built one day apart is quite small.

Now let's move back in time further. In figure 2, the purple line now shows a model that was built 2 weeks ago. Clearly there is model drift towards the lower predicted probabilities. If the use case primarily depended on the higher predicted probabilities, this 2 week old model probably was sufficient. If the lower predicted probabilities are used in the model application, then it is probably time to rebuild the model.

Moving back in time further, the orange line in Figure 3 below shows a model that was built 4 weeks ago. As you can see, the orange line visibly deviates from the reference model both in high and low predicted probabilities. Clearly this 4 week old model is no longer useful.

More importantly using outdated drifted models could actually negatively impact game or app performance. Imagine that the game here is identifying users with the highest probabilities for special treatment. By using the 4 week old model, we would be missing many users who fit the target description.
To ensure comparability across the different models in the above example, they were all built with the same set of features and observations available at the time of building. Additionally these models did not cross any significant seasonal thresholds.
The most obvious result is that models rebuild must be factored into the budget and plans of a data science team. The rate of model drift will determine how frequently the model rebuild occurs. Additionally model propagation into the production scoring process must also follow each model rebuild. In some cases, it is not unusual for a data scientist to be fully utilized supporting 4 models that need weekly rebuilds. There are model management tools available for licensing, including the venerable SAS Enterprise, as well as upstarts such as DataRobot and Dataiku. As with all tools, they come with their own trade offs. Another option are service outfits, such as Sonamine, that provide end-to-end model scoring. Such service companies reduce the complexity of data and model management, in exchange for less model customization and explainability.
A well executed model refresh strategy separates the winners from the rest, according to a McKinsey survey of AI in 2020. Automated model refreshing is a core foundational principle behind the Sonamine predictive scoring service, allowing our customers to use AI in CRM without a large initial investment. What's your model refresh rate? Contact us to compare notes!
Reference
1. https://www.mckinsey.com/business-functions/mckinsey-analytics/our-insights/global-survey-the-state-of-ai-in-2020
For a limited time until December 2025, Sonamine is offering a 60 day money back guarantee to OneSignal customers. Come experience the ease and simplicity of the First Time Spender Nudge package and watch your conversions soar.
For a limited time until December 2025, Sonamine is offering a 60 day money back guarantee to OneSignal customers. Come experience the ease and simplicity of the First Time Spender Nudge package and watch your conversions soar.